Discovery App¶
Discovery App service to connect and crawler provider
- Encharge to manager and authenticate in each provider
- Crawler the data and record into db
- Consume batch insert data
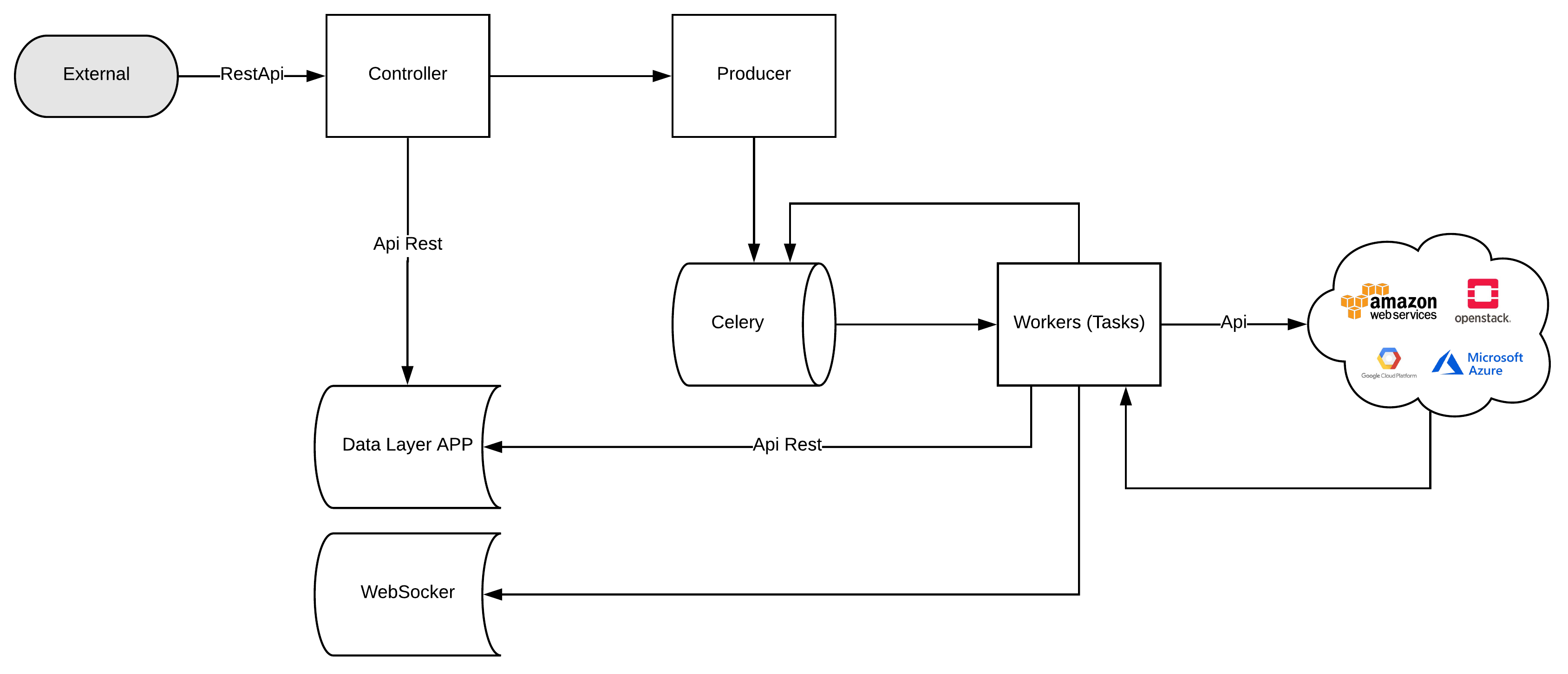
Discovery using Flask, and python >3.5, has api rest, and tasks.
Setup dev env
cd devtool/
docker-compose up -d
Will be setup rabbitmq and redis
Windows Env
If you use windows, celery havent support for windows, the last version is 3.1.25.
pip3 install celery==3.1.25
npm run powershell
Important topics
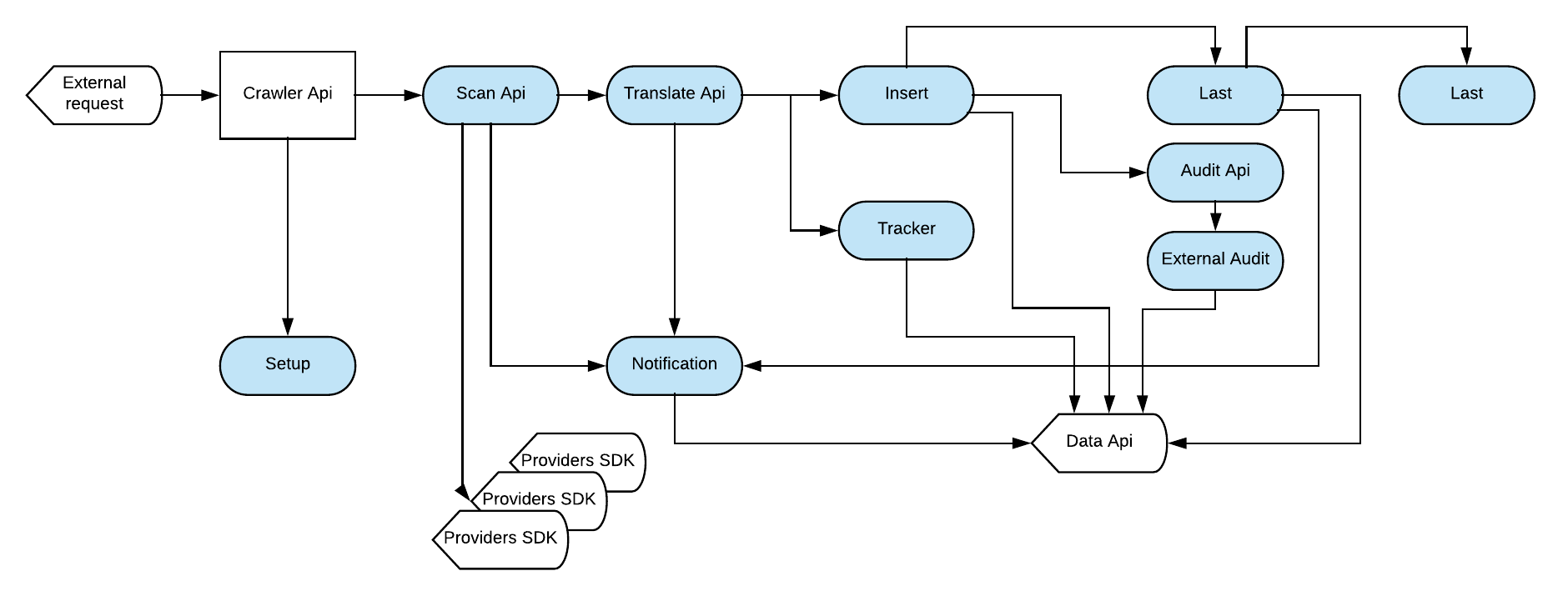
Controller used factory dc abstract to create easy way to make CRUD in mongodb
The crawler is divided in:
- api: connect in api provider and get result
- translate: normalize the data
setup: reset tracker stats (used in datacenters to ensure a sync resource)
tracker: add list entry into tracker stats
- insert: insert/update data in mongodb
audit: prepare and transform data to be send record to external audit task
external_audit: Send http request to Audit app
ws: Send http notification to webscoket api
Each step have unique task.
Config is managed by env variables, need to be, because in production env like k8s is easier to manager the pods.
Repository has pymongo objects.
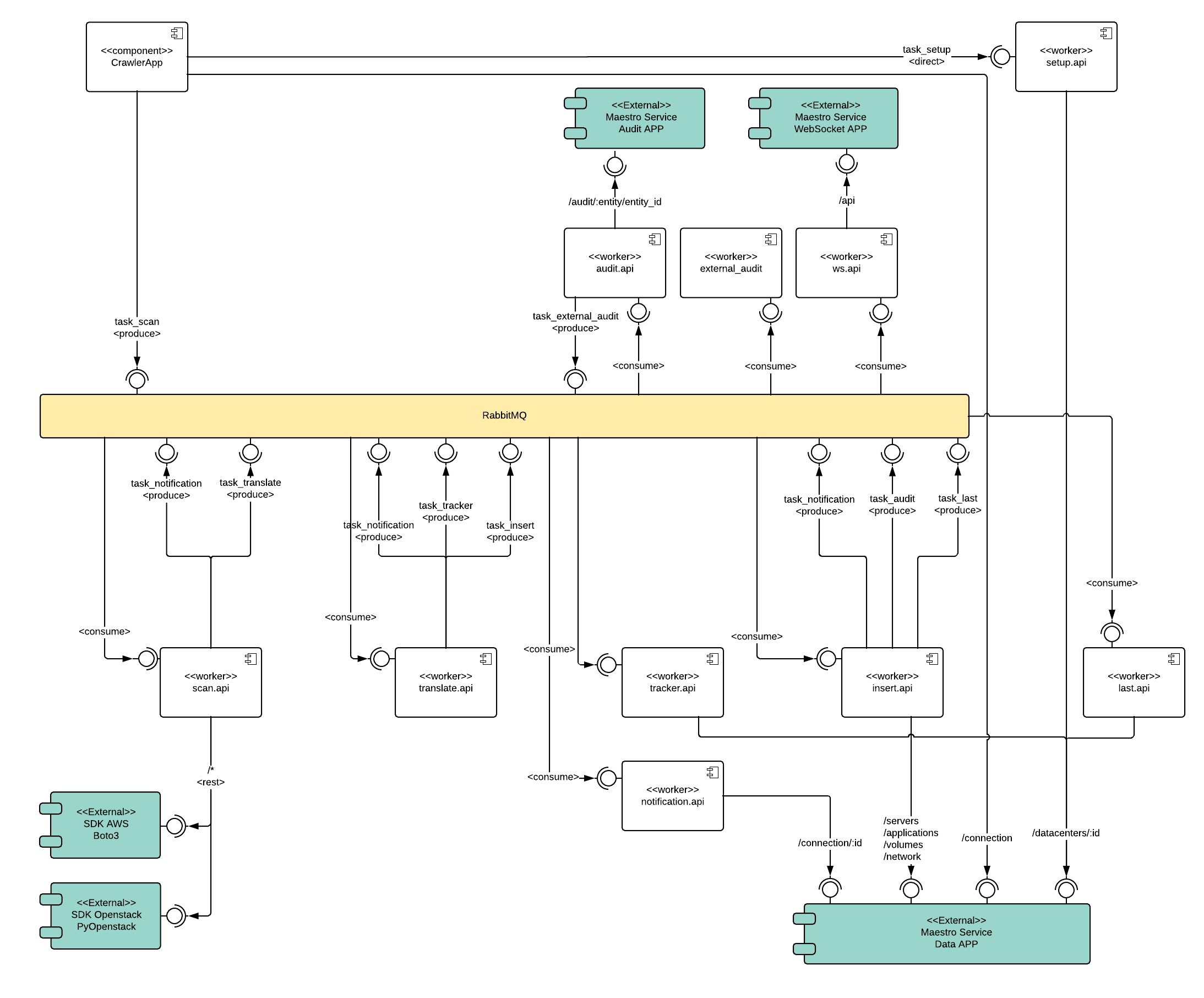
Component Diagram
Follow the component diagram to show a relation of each worker and service.
Flower - Debbug Celery
You can install a flower, it’s a control panel to centralize results throughout rabbitMQ, very useful to troubleshooting producer and consumers.
pip install flower
flower -A app.celery
npm run flower
Installation with python 3
- Python >3.4
- RabbitMQ
Download de repository
git clone https://github.com/maestro-server/discovery-api.git
Install dependences
pip install -r requeriments.txt
Install run api
python -m flask run.py
or
FLASK_APP=run.py FLASK_DEBUG=1 flask run
or
npm run server
Install run rabbit workers
celery -A app.celery worker -E -Q discovery --hostname=discovery@%h --loglevel=info
or
npm run celery
Warning
For production environment, use something like gunicorn.
# gunicorn_config.py
import os
bind = "0.0.0.0:" + str(os.environ.get("MAESTRO_PORT", 5000))
workers = os.environ.get("MAESTRO_GWORKERS", 2)
Env variables
| Env Variables | Example | Description |
|---|---|---|
| MAESTRO_PORT | 5000 | Port used |
| MAESTRO_DATA_URI | http://localhost:5010 | Data Layer API URL |
| MAESTRO_AUDIT_URI | http://localhost:10900 | Audit App - API URL |
| MAESTRO_WEBSOCKET_URI | http://localhost:8000 | Webosocket App - API URL |
| MAESTRO_SECRETJWT | XXX | Same that Server App |
| MAESTRO_SECRETJWT_PRIVATE | XXX | Secret Key - JWT private connections |
| MAESTRO_NOAUTH | XXX | Secret Pass to validate private connections |
| MAESTRO_WEBSOCKET_SECRET | XXX | Secret Key - JWT Websocket connections |
| MAESTRO_TRANSLATE_QTD | 200 | Prefetch translation process |
| MAESTRO_GWORKERS | 2 | Gunicorn multi process |
| CELERY_BROKER_URL | amqp://rabbitmq:5672 | RabbitMQ connection |
| CELERYD_TASK_TIME_LIMIT | 10 | Timeout workers |